Publicado: 2021-11-4 por Rafael Rocha
Introdução
A universidade é um dos alicerces do desenvolvimento de um país. As pesquisas e a formação profissional garantem o desenvolvimento de um povo (SGUISSARDI, 2005). As pesquisas realizadas na universidade pública devem ser amplamente divulgadas para o aproveitamento completo dos recursos utilizados. Da mesma maneira os dados envolvidos nas pesquisas devem ser disponibilizados para o conhecimento público, além de contribuir em pesquisas correlatas em outras instituições. A web semântica é ideal para publicar dados mantendo o sentido estabelecido pelo autor, ainda permite o reuso de dados oriundos de outras fontes.
A web semântica é a extensão da web convencional (BERNERS-LEE; HENDLER; LASSILA, 2001). Enquanto na web convencional os hipertextos e links estão publicados sem compromisso de um significado interoperável. A web semântica permite a publicação de hipertextos com significado definido, além disso, o significado é compartilhado por pessoas e computadores. O Linked Data (LD) é a conexão dos dados por meio de Uniform Resource Identifier (URI) (BIZER; HEATH; BERNERS-LEE, 2011). O LD possui um método eficaz de publicar os dados com semântica explícita, além de permitir incorporar licenciamento e proveniência. O LD reúsa conceitos disponibilizados na web possibilitando um enriquecimento dos dados, desse modo oferecendo dados com maior abrangência e complexidade aos pesquisadores .
Quais as tecnologias semânticas necessárias para iniciar a publicação de LD nas universidades públicas? Uma vez que não existe orientação oficial ou formal de como o LD deve ser adotado. Ao longo do tempo os serviços públicos vem utilizando o LD, mas precisa de mais adesão das universidades públicas. A hipótese é que existem diversas ferramentas e técnicas com baixo custo de adesão para fomentar a publicação do LD.
Web Semântica
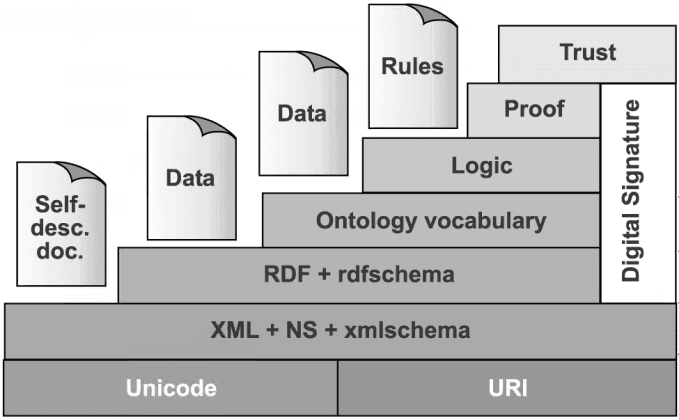
A Figura demonstra as camadas da web semântica, apresentando na camada base o sistema de codificação de caracteres Unicode e o URI para apontar os recursos utilizados no LD (SURE; STUDER, 2005). Desse modo, todos os recursos possuem um identificador único por meio da URI e todos os caracteres de todas as línguas estão mapeados pelo Unicode.
A camada seguinte forma a estrutura fundamental do LD na web semântica (YONG- GUI; ZHEN, 2010). A camada é composta por XML, NameSpace (NS) e XML Schema. O XML é uma linguagem de marcação que utiliza tags de forma hierárquica para relacionar valores de um determinado objeto. Já o NS utiliza uma URI apontando para a origem do valor ou conceito, assim garante que não ocorra conflitos no XML. Por fim, o XML Schema provê mais assertividade na atribuição de valores aos dados.
Já na camada acima da web semântica, proporciona semântica ao LD (YONG-GUI; ZHEN, 2010). O Resource Description Framework (RDF) é representado por um grafo direcionado constituído por um sujeito, predicado e objeto (W3C Recommendation, 2021). O objeto afere valor ao sujeito da declaração RDF, enquanto o predicado atribui o tipo da relação sujeito/objeto. Esses elementos do LD fazem declaração sobre coisas e seus valores. O Resource Description Framework Schema (RDFS) provê taxonomia para o RDF, assim é possível representar relação de subsunção, ou seja, estabelecer uma hierarquia nos elementos do LD.
A camada de vocabulário ontológico da web semântica insere os conceitos de conhecimento compartilhado das ontologias no LD (YONG-GUI; ZHEN, 2010). Além disso, atribui mais significado a taxonomia do RDFS, desse modo é possível descrever com maior exatidão dos elementos do LD.
Seguinte, a camada de lógica (logic), provê inferências lógicas no LD, já a camada prova (proof ) e confiança (trust) geram a confiabilidade nos dados por meio da proveniência dos dados e certificados digitais (YONG-GUI; ZHEN, 2010).
Portanto, o LD é obtido a partir do RDF, gerando vocabulário com maior expressividade por intermédio das ontologias, ou seja, com as ontologias o LD consegue representar por completo determinado conhecimento.
Universidades e LD
O desenho da ontologia é o primeiro passo para publicação do LD. O reúso de ontologias (ou vocabulários ontológicos) permite maior interoperabilidade do LD (PEREIRA et al., 2017; NAHHAS et al., 2018). Ao descrever o conhecimento sobre coisas na web semântica é necessário um meio comum dos significados. As ontologias aprimoram a descoberta e reúso do LD para educação. O Dublin Core é um vocabulário ontológico que descreve objetos digitais tais como hipertextos, vídeos, imagens entre outros. Ao passo que o BIBO é a extensão do Dublin Core e possui mais vocabulário para representar ontologicamente a bibliografia. Da mesma maneira, o ALOCoM descreve objetos digitais, no entanto com viés pedagógico ou instrucional. Já o LOCO é uma ontologia com foco no processo de aprendizagem, modelando interação do estudante e professor, além dos conteúdos didáticos. Por fim, o AIISO modela ontologicamente a estrutura interna acadêmica.
A manutenção das ontologias é realizada por editores de ontologias. Essas ferramentas facilitam a visualização dos conceitos, além de auxiliar na validação do conhecimento e evitar erros humanos (SURE; STUDER, 2005). Nesse sentido, destacam-se o Protégé e KAON. Já o OOPS! valida a ontologia utilizando algumas heurísticas comumente utilizadas na modelagem. Portanto, essas ferramentas auxiliam a construção da ontologia com um conhecimento coeso, reaproveitando o vocabulário de outras ontologias.
Diversos dados estão armazenados em formatos tradicionais, como em arquivos texto ou banco de dados relacionais, desse modo é necessário utilizar ferramentas de mapeamento para converter o dado tradicional em dado semântico, ou seja, o LD (SURE; STUDER, 2005; NAHHAS et al., 2018). Esse processo automatizado é possível por meio de um interface ou mapeamento em que a ontologia é associada com os dados tradicionais. O D2RQ10 converte banco de dados relacional em LD. Já o Triplify converte para LD arquivos textos de diversos formatos. Por fim, Tripliser converte somente XML para LD.
Após gerar o LD é possível armazená-los em seu estado semântico fazendo uso dos triplestores (PEREIRA et al., 2017; NAHHAS et al., 2018). Os triplestores são banco de dados para o LD, permitindo incrementalmente salvar novos dados, além de oferecer meios de recuperar somente os dados necessários. Os triplestores a seguir são alguns exemplos de ferramentas que possuem suporte ao LD: AllegroGraph, Apache Jena Fuseki, OpenLink Virtuoso, BigOWLIM, entre outros.
A publicação do LD é realizada na web, disponibilizando todo o LD ou fragmentos interligados (PEREIRA et al., 2017). A abordagem de publicação interfere diretamente como o LD é gerado, portanto, outras ferramentas devem ser adotadas para cada necessidade.
Por fim, os resultados iniciais dessa investigação trouxeram resultados relevantes para a utilização do LD na universidade pública. Existe vasta fonte de ontologias e ferramentas, em sua maioria com licenciamento livre, ou seja, permite alterá-los com autorização prévia. Desse modo, as universidades públicas podem compartilhar seus dados semanticamente com seus diversos benefícios por meio do LD.
Considerações finais
As pesquisas e os dados produzidos devem estar disponíveis para toda a sociedade. O LD é uma forma eficiente para publicar os dados com semântica explícita, além de possibilitar o reúso de dados de outras instituições. O LD da educação não é diferente de qualquer outro LD. Já a ontologia para educação é bastante distinta, no entanto foram encontradas diversas ontologias e vocabulários ontológicos a disposição para reúso.
REFERÊNCIAS
BERNERS-LEE, T.; HENDLER, J.; LASSILA, O. The semantic web. Scientific american, JSTOR, v. 284, n. 5, p. 34–43, 2001.
BIZER, C.; HEATH, T.; BERNERS-LEE, T. Linked data: The story so far. In: Semantic services, interoperability and web applications: emerging concepts. [s.l.]: IGI global, 2011. p. 205–227.
NAHHAS, S. et al. Added values of linked data in education: A survey and roadmap. Computers, Multidisciplinary Digital Publishing Institute, v. 7, n. 3, p. 45, 2018.
PEREIRA, C. K. et al. Linked data in education: a survey and a synthesis of actual research and future challenges. IEEE Transactions on Learning Technologies, IEEE, v. 11, n. 3, p. 400–412, 2017.
SGUISSARDI, V. Universidade pública estatal: entre o público e privado/mercantil.Educação & Sociedade, SciELO Brasil, v. 26, p. 191–222, 2005.
SURE, Y.; STUDER, R. Semantic web technologies for digital libraries. Library Management, Emerald Group Publishing Limited, 2005.
W3C Recommendation. RDF 1.1 XML Syntax. 2021. Disponível em: https://www.w3.org/TR/rdf-syntax-grammar/. Acesso em: 19 ago. 2021.
YONG-GUI, W.; ZHEN, J. Research on semantic web mining. In: IEEE. 2010 International Conference On Computer Design and Applications. [s.l.], 2010. v. 1, p. V1–67.
